



An effective team identification method requires both consideration of the definition of research teams and the ability to transform this definition into operable programming languages. University research teams, by definition, comprise researchers collaborating towards a shared objective. As a typical form of the output of a research team, the co-authorship of a scientific research paper implies information exchange and interaction among team members. Thus, this study uses co-authorship relationships within papers to reflect the collaborative relationships among research team members. In this section, novel algorithms for identifying research teams are proposed to address deficiencies observed in prior research.
Classification of research team members
A researcher might be part of multiple research teams, with varying roles within each. Members of the research team can be categorized according to how the research team is defined.
The original idea of team member classification
The prevailing notion of teams underscores the collaborative efforts between individual team members and their contributions toward achieving research objectives. This study similarly classifies team members based on these dual dimensions.
In terms of overall contributions, members who make substantial contributions are typically seen as pivotal figures within the research team, providing the primary impetus for the team’s productivity. Conversely, those with lesser input only contribute to specific facets of the team’s goals and engage in limited research activities, thus being regarded as standard team members.
In terms of collaboration, it is essential to recognize that high levels of contribution do not inherently denote a core position within a team. The collaboration among team members serves as an important indicator of their identity characteristics within the research team. Based on the collaboration between members, this study believes that researchers who have high contributions and collaborate with many high-contribution team members assume the core members of the research team. Conversely, members who have high contributions but only collaborate with a limited number of high-contribution team members are identified as backbone members. Similarly, members displaying low levels of contributions but collaborating widely with high contributors are categorized as ordinary members. Conversely, those with low contributions and limited collaboration with high-contributing team members are regarded as marginal members of the research team.
Establishment of team member classification criteria
This study introduces Price’s Law and Everett’s Rule to realize the idea of team member classification.
In terms of overall contribution, the well-known bibliometrics Price, drawing from Lotka’s Law, deduced that the number of papers published by prolific scientists is 0.749 times the square root of the number of papers published by the most prolific scientist in a group. Existing research also used this law when analyzing prolific authors of an organization. This study believes that prolific authors who conform to Price’s Law are important members who contribute more to the research team.
In terms of collaboration, existing research mostly employs the concept of factions. Factions refer to a relationship where members reciprocate and cannot readily join new groups without altering the reciprocal nature of their factional ties. However, in real-world settings, relationships with overtly reciprocal characteristics are uncommon. Therefore, to ensure the applicability and stability of the faction, Seidman and Foster (1978) proposed the concept of K-plex, pointing out that in a group of size n, when the number of direct connections of any point in the group is not less than n-k, this group is called k-plex. For k-plex, as the number k increases, the stability of the entire faction will decrease. Addressing this concern, renowned sociologist Martin Everett (2002), based on the empirical rule of research, proposed specific values for k and corresponding minimum group sizes, stipulating that the overall team size should not fall below 2k-1 (Scott, 2017). The expression is:
In other words, for a K-plex, the most acceptable definition to qualify as a faction is when each member of the team is directly connected to at least (n − 1)/2 members of the team. Applied to research teams, this empirical guideline necessitates that team members maintain collaborative ties with at least half or more of the team.
Based on Price’s Law and Everett’s Empirical Rule, this study gives the criteria for distinguishing prolific authors, core members, backbone members, ordinary members, and marginal members of research teams. The specifics are shown in the following Table 1.
Classification of research teams
Within universities, a diverse array of research teams exists, categorized by their scale, the characteristics of funded projects, and the platforms they rely upon. This study proposes the identification algorithms for project-based teams, individual-based teams, backbone-based groups, and representative groups.
Project-based research teams: identification based on research projects
Traditional methods for identifying research teams attribute co-authorship to collaboration among multiple authors without considering the time scope. However, in practice, collaborations vary in content and duration. Therefore, in the identification process, it is necessary to introduce appropriate standards to distinguish varying degrees of collaboration and content among scholars.
Research projects serve as evidence of researchers engaging in the same research topic, thereby indicating that the paper’s authors belong to the same research team. Upon formal acceptance of a research paper, authors typically append funding information to the paper. Therefore, papers sharing the same funding information can be aggregated into paper clusters to identify the research team members who completed the fund project. The specific steps proposed for identifying a single research project fund are as follows.
Firstly, extract the funding number and regard all papers attached with the same funding number as a paper cluster. Secondly, construct a co-authorship network based on the paper cluster. Thirdly, identify the research team using the team member classification criteria.
Individual-based research teams: team identification based on the first author
For research papers lacking project numbers, clustering can be performed based on the contribution and research experience of the authors. Each co-author of the research paper contributes differently to the paper’s content. In 2014, the Consortia Advancing Standards in Research Administration Information (CASRAI) proposed classification standards for paper contributions, including 14 types such as conceptualization, data processing, formal analysis, funding acquisition, investigation, methods, project management, resources, software, supervision, validation, visualization, paper writing, review, and editing.
In this study, the primary author of a paper lacking project funding is considered the initiator, while other authors are seen as contributors who advance and finalize the research. For papers not affiliated with any project, the first author and all their published papers form a paper group for team identification purposes. The procedure entails the following steps: Initially, gather the first author and all papers authored by them within the identification period to constitute a paper group. Subsequently, a co-authorship network will be constructed using the papers within the group. Lastly, the research team will be identified based on the criteria for classifying team members.
Backbone-based research group: merging based on project-based and individual-based research teams
Research teams can be identified either by a single project number or by individual researchers. Upon identification, it becomes evident that many research teams share similar members. This is because a research team may engage in multiple projects, and some members collaborate without funding support. While identification algorithms are suitable for evaluating the quality of a research article or funding, they may not suffice when assessing the research group, or they may not suffice when assessing the key factors affecting their performance. To address this, it is necessary to merge highly similar individual-based or project-based research teams according to specific criteria. The merged one should be termed a group, as it encompasses multiple project-based and individual-based research teams.
In the pursuit of building world-class universities, governments worldwide often emphasize the necessity of fostering research teams led by discipline backbones. In this vein, this study further develops a backbone-based research group identification algorithm, which considers project-based and individual-based research teams.
Identification of university discipline backbone members
Previous studies have summarized the characteristics of the university discipline backbones, revealing that these individuals often excel in indicators such as degree centrality, eigenvector centrality, and betweenness centrality. Each centrality indicator demonstrates a strong positive correlation with the author’s output volume, indicating that high-productive researchers with more collaborators are more inclined to be university discipline backbones. Based on these characteristics, Price’s law is applied, defining discipline backbone members as researchers whose publications count exceeds 0.749 times the square root of the highest publication count within the discipline.
Team identification with discipline backbone members as the Core
Following the identification of discipline backbones, this study consolidates paper groups wherein the discipline backbone serves as the core member of either individual-based or project-based research teams. Subsequently, backbone-based research groups are formed.
Merging based on similarity perspective
It should be noted that different discipline backbones may simultaneously participate as core members in the same individual-based or project-based research teams. Consequently, distinct backbone-based research groups may encompass duplicate project-based and individual-based research teams, necessitating the merging of backbone-based research groups.
To address this redundancy issue, this study introduces the concept of similarity in community identification. In the community identification process, existing algorithms often assess whether to incorporate members into the community based on their level of similarity. Among various algorithms for calculating similarity, the Jaccard coefficient is deemed to possess superior validity and robustness in merging nodes within network communities (Wang et al., 2020). Its calculation formula is as follows.
$$Similarity_jaccard^ij=(Ni\mbox\cap \mbox\,Nj)/(Ni\mbox\cup {\mbox}\,Nj)$$
Ni denotes the nodes within subset i, while Nj represents the nodes within subset j; Ni ∩ Nj signifies the nodes present in both subsets, whereas Ni∪Nj encompasses all nodes in subsets i and j. Existing research shows that when the Jaccard coefficient equals or exceeds 0.5 (Guo et al., 2022), the community identification algorithm achieves optimal precision.
In the context of this study, Ni represents the core and backbone members of research group i, while Nj denotes the core and backbone members of research group j. If these two groups exhibit significant overlap in core and backbone members, the papers from both research groups are merged into a new set of papers to identify the research team.
Given the efficacy of the Jaccard similarity measure in identifying community networks and merging, this study employs this principle to merge backbone-based research groups. Specifically, groups are merged if the Jaccard similarity coefficient between their core and backbone members equals or exceeds 0.5. Subsequently, new research groups are formed based on the merged set of papers.
It’s important to note that during the merging process, certain research teams within a backbone-based group may be utilized multiple times. Initially, the merging occurs based on the core and backbone members of the backbone-based research group, adhering to the Jaccard coefficient criterion. However, since project or individual-based research teams within a backbone-based research group may be reused, resulting in the similarity of research papers across different groups, the study further tested the team duplication of the merged papers of various groups. During the research process, it was found that the research papers within groups often exhibit similarity due to their association with multiple funding projects. Therefore, a principle of “if connected, then merged” was adopted among groups with highly similar research papers to ensure the heterogeneity of papers within the final merged research groups.
The generation process of the backbone-based research groups is illustrated in Fig. 1 below. Initially, university discipline backbones α, β, γ, θ, δ, and ε are each designated as core members within project-based or individual-based research teams A, B, C, D, E, and F, among which αβγ, γθ, θδ, δε ‘s core and backbone members’ Jaccard coefficient meet the merging standard and generate lines. After the first merging, the Jaccard coefficient of the papers of the αβγ, γθ, θδ, δε are calculated, and the lines are generated because of a high duplicated papers between γθ, θδ, and θδ, δε. Finally, αβγ and γθδε are retained based on the rule.

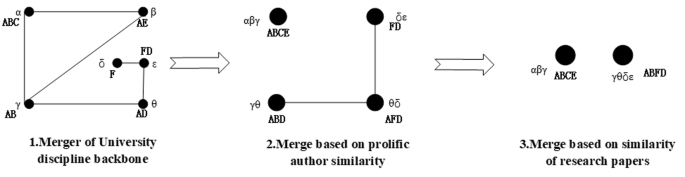
The α, β, γ, θ, δ, and ε are core members within project-based or individual-based research teams. The A, B, C, D, E, and F are project-based or individual-based research teams. From step 1 to step 2, research groups are merged according to the Jaccard coefficient between research team members. From step 2 to step 3, research groups are merged according to the Jaccard coefficient between research group papers.
In summary, the process of identifying a backbone-based research group involves the following steps: (1) Identify prolific authors within the university’s discipline by analyzing all papers published in the field, considering them as the discipline’s backbones members; (2) Merge the project-based and individual-based research teams wherein university discipline backbones are core member, thereby forming backbone-based research groups; (3) Merge the backbone-based research group identified in step (2) based on the Jaccard coefficient between their core and backbone members; (4) Calculate the Jaccard coefficient of the papers of the merged groups in step (3), merge the groups with significant paper overlap, and generate new backbone-based research groups.
The research groups identified through the above steps offer two advantages: Firstly, they integrate similar project-based and individual-based research teams, avoiding redundancy in team identification outcomes. Secondly, the same member may participate in different research teams, assuming distinct roles within each, thus better reflecting the complexity of scientific research practices.
Representative team: consolidation via backbone-based research group
When universities introduce their research groups to external parties, they typically highlight the most significant research members within the institution. Although the backbone-based research group has condensed the project-based and individual-based research teams, there may still be some overlap among members from different backbone-based research groups.
In order to create condensed and representative research groups that accurately reflect the development of the university’s discipline, this study extracts the core and backbone members identified in the backbone-based research group. It then identifies the representative group using the widely utilized Louvain algorithm (Blondel et al., 2008) commonly employed in research group identification. This algorithm facilitates the integration of important members from different backbone-based research groups while ensuring there is no redundancy among group members. The merging process is shown in Fig. 2.

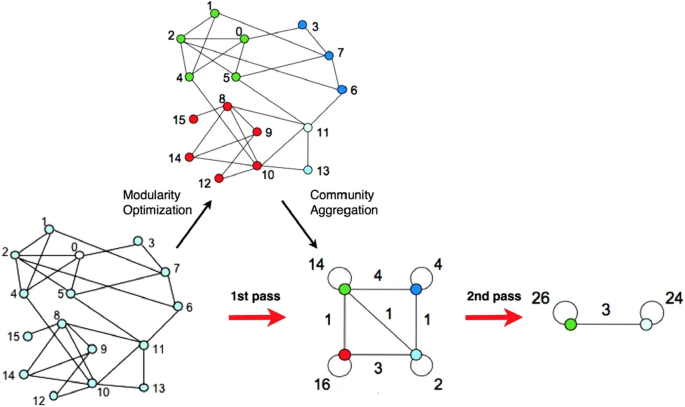
Each pass is made of two phases: one where modularity is optimized by allowing only local changes of communities, and one where the communities found are aggregated in order to build a new network of communities. The passes are repeated iteratively until no increase in modularity is possible.
Research team identification process and its pros and cons
Overall, the method of identifying university research teams proposed in this research encompasses four stages: Initially, research teams are categorized into project-based research teams and individual-based research teams based on information provided with research papers, distinguishing between those supported by funding projects and those not. Subsequently, the prolific authors of universities are identified to combine individual-based and project-based research teams, and backbone-based research groups are generated. Finally, representative research groups are established utilizing the Louvain algorithm and the interrelations among members within the backbone-based research groups. The entire process is depicted in Fig. 3 below.

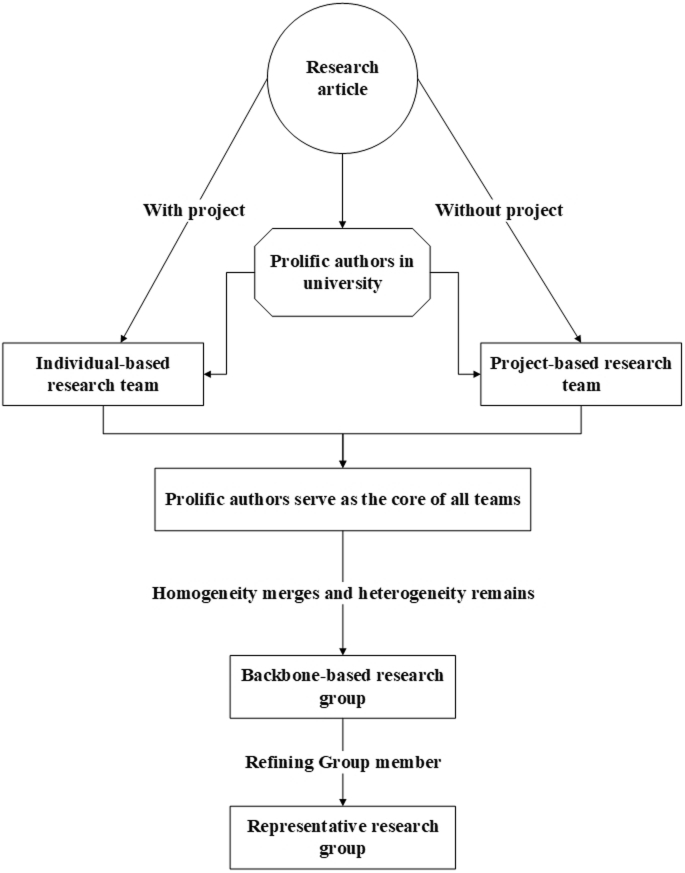
Different university research teams are identified at different stage.
Each type of research team or group has its advantages and disadvantages, as shown in Table 2 below.
Validation of identification results
In order to verify the accuracy of the identification results, the method proposed by Boyack and Klavans (2014), which relies on citation analysis, is utilized. This method calculates the level of consistency regarding the main research areas of the core and backbone members, thereby verifying the validity of the identification method.
In the SCIVAL database, all research papers are clustered into relevant topic groups, providing insights into the research area of individual authors. By examining the research topic clusters of team papers in the SCIVAL database, the predominant research areas of prolific authors can be determined. Authors sharing common research areas within a university are regarded as constituting a research team. Given that authors often conduct research in various research areas, this study focuses solely on the top three research areas for each author.
As demonstrated in Table 3 below, for the prolific authors A, B, C, D, and E of the research team, their top three research areas collectively span five distinct fields. By calculating the highest value of the consistency among these research areas, it can be judged whether these researchers can be classified as members of the same research group. As depicted in Table 3, the main research areas of all prolific authors include Research Area 3, indicating that this field is one of the three most important research areas for all prolific authors. This consistency validates that the main research areas of the five authors align, affirming their classification within the same research team.
Data collection and preprocessing
In order to present the distinct characteristics of various types of scientific research teams as intuitively as possible, this study focuses on the field of material science, with Tsinghua University and Nanyang Technological University selected for analysis. The selection of these two institutions is driven by several considerations: (1) both universities boast exceptional performance in the field of material science on a global scale, consistently ranking within the top 10 worldwide for numerous years; (2) The scientific research systems in the respective countries where these universities are situated differ significantly. China’s scientific research system operates under a government-led funding model, whereas Singapore’s system involves a multi-party funding approach with contributions from the government, enterprises, and societies. By examining universities from these distinct scientific research cultures, this study aims to validate the proposed methods and highlight disparities in the characteristics of their scientific research teams. (3) Material science is inherently interdisciplinary, with contributions from researchers across various domains. Although the selected papers focus on material science, they may also intersect with other disciplines. Therefore, investigating research teams in material science could somewhat represent the interdisciplinary research teams.
The data utilized in this study is sourced from the Clarivate Analytics database, which categorizes scientific research papers based on the subject classification catalogs. In order to ensure the consistency and reliability of scientific research paper identification, this study focuses on the papers published in the field of material science by the two selected universities between 2017 and 2021. Additionally, considering the duration of funded projects, papers associated with projects that have appeared in 2017–2021 within ten years (2011–2022) are also included for analysis to enhance the precision of identification. In order to ensure the affiliation of a research team with the respective universities, this study exclusively considers papers authored by the first author or the corresponding author affiliated with the university as the subject of analysis.
Throughout this process, it should be noted that the name problem in identifying scientific research. Abbreviations, orders, and other name-related information are cleaned and verified. Given that this study exports data utilizing the Author’s Full name and restricts it to specific universities and disciplines, the cleaning process targets the rectification of identification discrepancies arising from a minority of abbreviations and similar names. The specific cleaning procedures entail the following steps.
First, all occurrences of “-” are replaced with null values, and names are standardized by capitalization. Second, the Python dedupe module is employed to mitigate ambiguity in author names, facilitating the differentiation or unification of authors sharing the same surname, name, and initials. List and output all personnel names of each university in this discipline and observe in ascending order. Third, a comparison of names and abbreviations is conducted in reverse order, alongside their respective affiliations and replacements in the identification data. For example, names such as “LONG, W.H” “LONG, WEN, HUI” and “LONG, WENHUI” are uniformly replaced with “LONG, WENHUI.” Fourth, identify and compare similar names in both abbreviations and full forms and confirm whether they are consistent by scrutinizing their affiliations and collaborators. Names exhibiting consistency are replaced accordingly, while those lacking uniformity remain unchanged. For example, “LI, W.D” and “LI, WEIDE” lacking common affiliations and collaborators, are not considered the same person and thus remain distinct.
The publication of the two universities in the field of Materials Science and Engineering across two distinct time periods is shown in Table 4 below.
Based on the publication count of papers authored by the first author or corresponding author from both universities, Tsinghua University demonstrates a significantly higher publication output than Nanyang Technological University, indicating a substantial disparity between the two institutions.
Subsequent to data preprocessing, this study uses the Python tool to develop algorithms in accordance with the proposed principles, thereby facilitating the identification of research teams and groups.
link